

Learn - Share - Innovate - Elevate
DataOps Newsletter Volume 28 - April 2026

Learn
Blogs:
Love to share the blog I curated best of my knowledge for my Claude Certified architect
https://claude-architect.dataopslabs.com/

In Person Events:

Online Events:
Meetup:
Share
The AI Vulnerability Storm Is Here. Is Your Enterprise Ready?
Claude Mythos achieved a 72% exploit success rate across every major OS and browser — generating 181 working Firefox exploits autonomously, compared to 2 by the previous model. The patch window is no longer weeks. It’s under 20 hours.
This isn’t a single event — it’s a trajectory. From XBOW topping HackerOne in June 2025, to the first AI-orchestrated state espionage campaign in November, to 500+ open source zero-days in February 2026. Mythos is the acceleration, not the starting gun.
13 risks, 11 priority actions, mapped to NIST CSF 2.0, MITRE ATLAS, and OWASP Agentic 2026 — with time horizons from this week to 12 months. This is the Monday morning plan your CISO needs walking into the boardroom.
Internal applications are the highest-value targets — legacy ERP, shadow AI agents, citizen-coder pipelines. The post breaks down three breach scenarios with specific mitigations, and what a well-hardened enterprise actually looks like in practice.
Burnout is an operational risk. The briefing from 50+ CISOs is unusually direct: if you don’t add headcount and mandate AI agent adoption before the Glasswing patch wave hits, your most experienced people will be the first casualty.

Innovate
LinkedIn Post — DocLing + AWS Nova Pro: Nutrition Detection & Validation
🚀 Building an AI-powered Nutrition Label Detection & Validation System — here’s what I learned.
Nutrition labels look simple. But try to extract structured, machine-readable data from thousands of them — across scanned PDFs, product images, and mobile photos — and you’ll quickly discover one of the messiest document problems in food tech.
Here’s how I tackled it using DocLing + Amazon Nova Pro, and why this combination is a game-changer. 🧵
GitHub Link - https://github.com/dataopslabs-aws/nutrition-detection-validation
🧩 The Problem
Nutrition labels come in every shape, size, and format imaginable:
Scanned PDFs with skewed tables
Product images with varying fonts, layouts, and lighting
Manufacturer documents with custom structures that don’t follow any standard template
Traditional OCR tools fail here. They can read text but have no understanding of structure — they can’t tell you that “Saturated Fat 2g” belongs to a nutrition facts table, not a marketing tagline. You need something smarter.
🔬 Enter DocLing — Document Intelligence at Scale
DocLing by IBM Research is an open-source document AI library that goes far beyond OCR. It understands document layout — tables, sections, headers, list items — and converts them into structured, queryable formats.
In this project, DocLing runs as a containerized microservice on AWS Fargate, giving us:
✅ Layout-aware parsing — it recognizes the nutrition facts table as a table, not random lines of text ✅ PDF + image ingestion — handles both scanned PDFs and uploaded label images ✅ Structured output — JSON representations of extracted entities ready for downstream processing ✅ Horizontal scalability — Fargate auto-scales based on demand, so a burst of label uploads doesn’t bottleneck the system
The DocLing Fargate service is the backbone of the document understanding pipeline. Without it, everything downstream would be guessing.
👁️ Amazon Nova Pro — Visual Intelligence for What DocLing Can’t See
Some labels can’t be parsed from PDFs — they live only as product photos. That’s where Amazon Nova Pro steps in.
Nova Pro is Amazon’s multimodal foundation model, built for understanding both text and images with state-of-the-art accuracy. In our architecture, it powers the analyze_image_handler — a service that:
🔍 Identifies nutrition panels within complex product imagery (even partial or angled shots) 📊 Extracts key nutrition entities — calories, macros, allergens, serving sizes — directly from visual content ⚡ Integrates with Strands Agents — the extracted data feeds directly into an agentic compliance pipeline
The combination is powerful: DocLing handles the structured document side, Nova Pro handles the raw image side. Together, they cover virtually every format a nutrition label comes in.
🏗️ The Architecture (simplified)
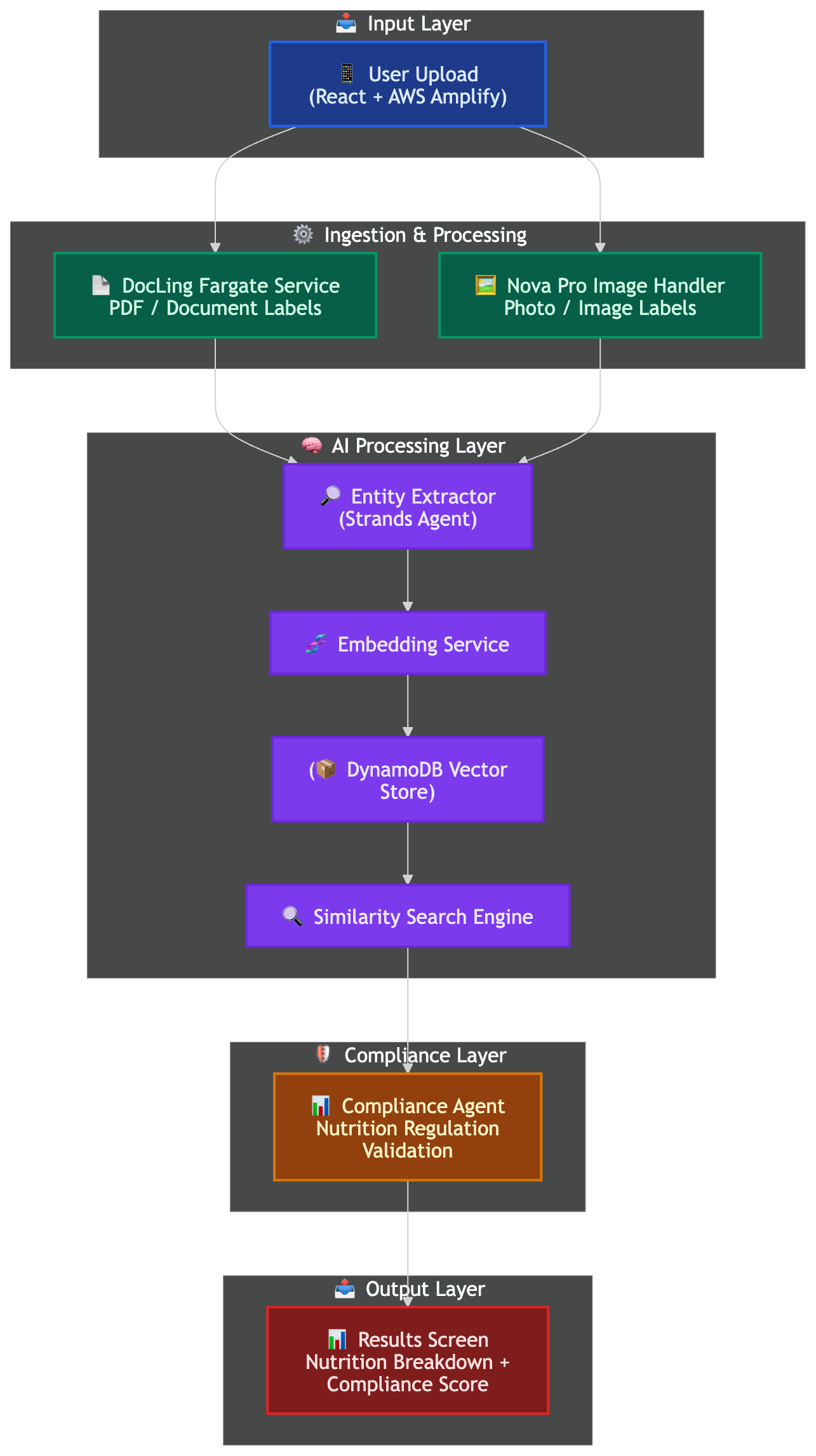
Three AWS CDK stacks keep this clean:
DocLing Fargate Stack — containerized document processing
Similarity Engine Stack — vector embeddings + DynamoDB for semantic search
Amplify Hosting Stack — React frontend
💡 Key Lessons Learned
1. Don’t fight document structure — understand it. OCR alone is a dead end for semi-structured documents like nutrition labels. DocLing’s layout-awareness is what makes extraction actually reliable.
2. Multimodal AI is no longer optional in real-world pipelines. A huge percentage of product data lives in images. Nova Pro bridges the gap between visual content and structured data extraction.
3. Agents make compliance validation tractable. Using Strands Agents to orchestrate the compliance checking pipeline let me define rules declaratively and let the agent handle the edge cases — instead of writing endless if/else logic.
4. Vector search changes what “validation” means. Rather than hard-coding nutrition thresholds, the similarity engine finds semantically related products and flags anomalies. It’s validation that gets smarter with more data.
If you’re working on document AI, food tech, or building intelligent validation pipelines — I’d love to connect and trade notes. Drop a comment or DM me! 👇
#DocLing #AWSNovaPro #GenerativeAI #DocumentAI #FoodTech #MLEngineering #AWS #BuildingInPublic #AmazonBedrock #AIAgents
Elevate

PODCAST : The AI Vulnerability Storm: An Enterprise CISO Readiness Guide
By: Ayyanar Jeyakrishnan
Disclaimer “AI Generated Podcast” but content curated by me
Thanks for TRESIDUS for sponsoring this blog